Jan 9, 2026 · 11 min read
Why I'm Building Evals Before Features: Evaluator-First Architecture
Most AI developers ship first and evaluate later. I'm flipping that order - here's why building your evaluation system first might be the key to shipping AI that actually works.
TL;DR
- Many AI projects struggle because teams can't measure what "good" looks like
- Traditional TDD doesn't translate cleanly to LLMs - outputs aren't deterministic
- Building your evaluation system first forces clarity on success criteria
- I'm calling this "Evaluator-First Architecture" - the eval agent is the first thing you build
- My hypothesis:
- Evaluator-first architecture improves output quality compared to building features first
- Multiple evaluators provide better coverage, but with diminishing returns after a certain point
How do you know if your AI feature actually works?
That question has been stuck in my head since I started building with AI agents. And honestly? I didn't have a good answer. I was doing what most people do: ship something, try it a few times, decide it "feels right," and move on.
That's called vibe-based development. And it's a trap.
Here's the problem - LLMs don't fail like traditional code. When a function breaks, you get an error. When an LLM fails, it just... confidently gives you something wrong. No stack trace. No red squiggly line. Just plausible-sounding garbage that slips into production.
I've been there. You probably have too.
The Ecosystem Problem
Look at the Claude Code ecosystem right now. Skills, plugins, hooks - people are shipping them constantly. It's exciting. It's also a mess.
How are these tools being evaluated? Mostly, they're not. The typical workflow looks like this:
- Build the thing
- Run it a few times manually
- Decide the output looks "good enough"
- Ship it
That's not evaluation. That's anecdotal evidence dressed up as validation.
And here's the uncomfortable truth: quality degrades over time. Models change. Dependencies update. Edge cases emerge. But nobody goes back to re-evaluate their shipped skill six months later. Why would they? There's no system telling them something broke. There's no metric showing quality dropped from 85% to 60%.
The result is an ecosystem full of tools that worked once, for one person, in one context - and now silently fail in ways nobody notices.
There's another failure mode that's even more insidious: patience degradation. When you're iterating on prompts without clear metrics, every tweak is a roll of the dice. Maybe it helps, maybe it makes things worse - you can't really tell. After enough iterations, something breaks in your motivation. You've tried dozens of variations. Nothing feels definitively better. And when the next problem surfaces, you don't think "let me fix this." You think "I've already tried everything. I'm just going to live with it."
At that point, you're stuck with a poorly written prompt that nobody is going to fix. It either keeps causing friction forever or eventually gets deprecated - not because it couldn't be improved, but because everyone ran out of patience to try.
This isn't a criticism of the people building these tools. They're doing the best they can with the tools available. The problem is that the tools for measuring "good" in AI outputs barely exist. So everyone defaults to vibes.
I want to break that cycle. But first, I need to understand what we're working with.
The TDD Parallel That Doesn't Quite Work
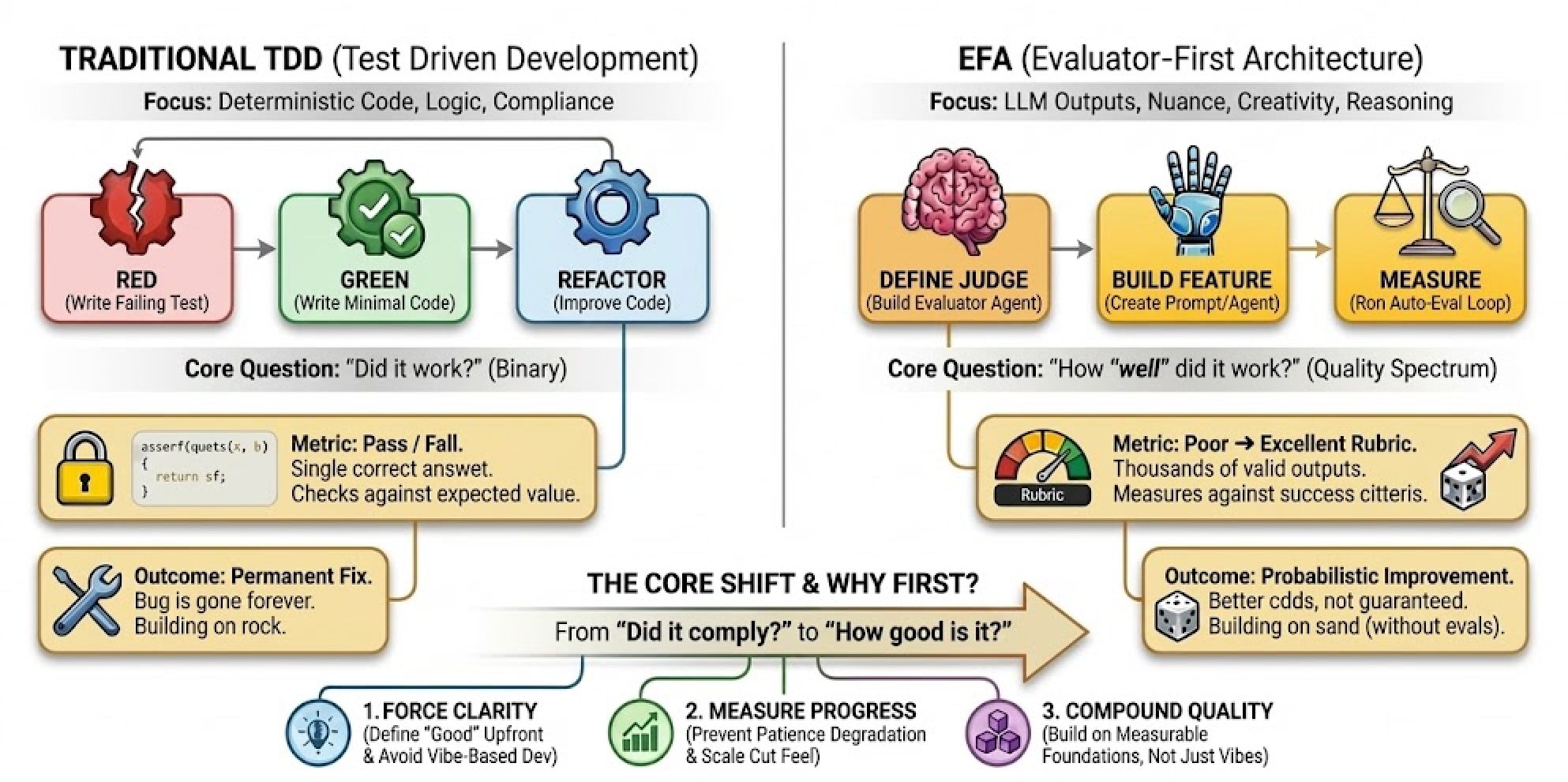
If you've written tests before, you know the TDD mantra: write the test first, then write the code that passes it. Red, green, refactor. Simple.
But TDD assumes something critical: for a given input, there's one correct output.
LLMs break that assumption completely.
Ask an AI to write an email, and there are thousands of valid outputs. Ask it to summarize a document, and "correct" becomes subjective. The deterministic world of unit tests doesn't map cleanly here.
There's another critical difference: foundational quality compounds differently. With traditional code, if you hit a bug in production, you write a test, fix the bug, push the change, and that specific bug never happens again. It's fixed forever.
With LLMs, you don't get that guarantee. Because they're non-deterministic, a fix isn't really a fix - it's a probabilistic improvement at best. And this has massive implications for anything you build on top. If your foundational tools don't have solid, consistent, measurable quality metrics, then every downstream product inherits that uncertainty. You're not building on rock - you're building on sand, and just hoping it holds.
So what do you do instead?
The Superpowers Approach
Jesse Vincent's Superpowers plugin for Claude Code applies TDD principles to skill creation itself. His methodology is rigorous: watch agents fail without a skill (RED), write the minimal skill to fix it (GREEN), then close loopholes through iteration (REFACTOR). It's excellent work, and the discipline it brings to agent workflows is real.
Jesse's tests answer a specific question: did the agent comply with the skill? Did it follow the rules? That's a binary outcome - pass or fail. And for enforcing agent behavior, it works.
But I'm trying to answer a different question: how good is the output?
That's not a test. That's an evaluation. And the difference matters.
Tests vs. Evals
Tests are binary. Pass or fail. Did the function return the expected value? Did the agent follow the skill's instructions? There's a correct answer, and you check against it.
Evals are different. They measure quality across dimensions. There's no single "correct" output - there's a spectrum from poor to excellent. An eval asks: How clear is this writing? How accurate is this summary? How well does this code handle edge cases?
You can't assertEquals() your way to quality measurement. You need rubrics, criteria, judgment.
Jesse's TDD approach validates that agents do the thing. My evaluator-first approach tries to measure how well they did it. Both matter. But they solve different problems.
Right now, I'm iterating without a clear metric to grade output quality. That's the gap I need to fill. Before I can build workflows on top of agent outputs, I need to build the thing that tells me whether those outputs are actually good.
Enter Evaluator-First Architecture
Here's where my thinking shifted. Instead of asking "did the output match my expected string?" I started asking "does this output meet my criteria for success?"
That's a fundamentally different question. And it requires a fundamentally different system to answer it.
I'm calling this approach Evaluator-First Architecture - the practice of building your evaluation agent before building the feature it evaluates. The idea is simple:
- Before you build the feature, build the thing that judges the feature
- Define what "good" looks like in concrete, measurable terms
- Let a dedicated worker - an eval agent - run those judgments automatically
Why First?
Building evals after the feature is like writing tests for code you've already convinced yourself works. You're biased. You'll write tests that pass, not tests that challenge.
When you build the evaluator first, you're forced to answer hard questions early:
- What does success actually look like? Not vaguely - specifically
- What are the failure modes? You have to imagine them before you've seen them
- How will you measure quality? Gut feel doesn't scale
This is the same discipline TDD brings to traditional code. The order matters.
What I'm Still Figuring Out
I won't pretend I've solved this. There are real challenges:
- Eval design is hard. Defining good criteria requires domain knowledge and iteration
- LLM-as-judge has limits. Using one LLM to evaluate another introduces its own biases
- The cold start problem. You need examples to build evals, but you need evals to generate good examples
I'm actively working through these. The approach isn't perfect, but it's already changed how I think about building AI features.
The goal isn't perfect evals. It's moving from "I think this works" to "I can measure whether this works."
How This Compares to Industry Practice
In a recent conversation, Hamel Husain and Shreya Shankar shared practical wisdom on evals that's worth engaging with. They're deep in this space, and their advice is grounded in real production experience.
Where we align:
- Human insight is non-negotiable. Shreya is emphatic: you can't just "buy" a tool to handle evals for you. Human judgment is required to define quality. This matches my core premise - there's no escaping the need to anchor evaluation to human standards.
- Look at your data. Hamel calls reading logs and traces "the highest ROI activity for improving an AI product." I completely agree. You can't evaluate what you don't observe.
- Integrate into workflows. They recommend putting evals into CI/CD and sampling production traces daily. I'm not there yet, but this is clearly the right direction - offline iteration plus online monitoring, feeding back into each other.
Areas I need to investigate further:
Shreya suggests most teams need only 4-7 LLM-as-judge prompts. That's surprisingly small - and might be right for many product teams. But I'm building something different: a rubric with 8 quality dimensions (clarity, completeness, coherence, etc.) that apply universally across artifacts.
The difference is scope. Their evals are issue-specific, tailored to particular failure modes: "Is the model saying something offensive?" Mine are universal quality dimensions meant to apply across any artifact - covering both how it's constructed (clarity, completeness, coherence) and what it produces (outcome validity). Both approaches are valid. But I haven't yet tested whether 8 dimensions is the right number, or whether some could be collapsed without losing signal.
They also argue for ruthless prioritization: not every issue needs a formal eval. Focus on persistent "pesky" problems and high-risk failures. Fix what you can with prompts; only eval what keeps coming back. Pragmatic advice, but I'm not sure it applies to my use case. When you're building an evaluator that will assess other artifacts, can you afford to skip dimensions? Or does that create blind spots that propagate downstream? I don't know yet.
The "vibes" question:
They make a nuanced point about the "evals vs. vibes" debate: teams that claim to rely on vibes are often doing rigorous evaluation through dogfooding and manual error analysis - they just don't call it "evals."
Hamel notes that coding agent teams can "short-circuit" the process because developers are both the builders and the domain experts. Constant personal testing substitutes for formal evaluation.
This is where my situation gets interesting. I am building agent tooling. I am the domain expert dogfooding my own product. By their logic, maybe I could rely on vibes.
But I'm not convinced. Here's why:
-
Dogfooding has limits. I can test my own workflows, but I can't anticipate every user's context. Formal evals force me to define success criteria that generalize beyond my personal use cases.
-
Memory is unreliable. When I'm deep in iteration, I forget what "good" looked like three versions ago. Calibrated evals give me a stable reference point.
-
Vibes don't compound. If I build a skill builder on top of an evaluator on top of a prompt library, each layer inherits uncertainty from below. Rigorous evaluation at each layer is how I prevent that uncertainty from compounding into chaos.
Different contexts, different trade-offs:
If you're a product team shipping features to users, their advice is probably right. Get something working, look at logs, iterate fast. Evals are a tool to surface problems - they don't need to be perfect to be useful.
But I'm building foundational infrastructure that other systems will depend on. The evaluator isn't a means to improve something else - it is the thing I'm building. A miscalibrated evaluator doesn't just produce one bad assessment; it creates systematic drift across everything that trusts it. That's why I'm investing in calibration upfront.
What's Next
I'm building out my evaluator system right now, and I have specific hypotheses I want to test:
First: Does evaluator-first architecture actually improve output quality? I believe it does, but belief isn't data. I need to prove this approach works before building on top of it.
Second: How does the number of evaluators affect results? Are there diminishing returns as you add more evals, and where is that inflection point?
I suspect there's a sweet spot - too few evals and you miss failure modes, too many and you're burning tokens without meaningful improvement. Finding that curve could change how we think about eval investment. But first, I need to validate the foundation.
Future posts will cover:
- The architecture - how I'm structuring evaluators as agents
- Practical examples - real evals I've built and what they caught
- The numbers - testing my hypothesis about eval quantity vs. quality
- Tooling - what's out there and what's missing
- Mistakes - because I'm definitely making them
If you're building AI features and relying on vibes to know if they work, consider flipping your process. Build the judge before the defendant.
The question isn't whether your AI works. It's whether you can prove it.